In-house LLM-application by Spring AI + Ollama

Introduction
Hello everyone, another of LLM blog post from product backend developer 😂 . In this blog post, We are going to explore more about Spring AI + Ollama.
Spring Boot, If we discuss in Java developer community, no one not know about this wonderful framework for sure. And recently, Spring team has been developing the way to integrated to LLM. As a developer, Our time for expanding knowledge has come.
Anyway, I wrote another blog post about LangChain4j which it’s able to integrate to Spring Boot as well. Feel free to check if you interested.
Okay, Let’s start our Spring AI + Ollama project
Prerequisites
LLM (Large Language Models)

AI model that are created from large dataset for thinking and generating the ideas/contents like human. On each model has its own Pros depend on the purpose of training and the using dataset. Some of them are using in general context, some of them able to using in special way e.g. Coding and etc.
Well-known example
- GPT-3/4 (OpenAI)
- Llama 2 (Meta)
Ollama

Ollama — The one of option that you can run LLM on your laptop or container to serve open-source LLM. So you don’t need to connect AI provider directly e.g. GPT model from OpenAI but using alternative model as alternative.
As of now, There are many options for Ollama. For example, Mistral, Llama2, Gemma, and etc. And we can interact with them by using CLI (Command Line Interface), REST API and SDK (Software Development Kit).
Checkout below sites for more informations

RAG (Retrieval-Augmented Generation)
Retrieval-Augmented Generation (RAG) is the process to optimizing output of LLM by adding knowledge base as extras from the trained data before the model make the response/answer.
- Generation is meaning LLM generate data from user query and create the new result base on the knowledge of LLM
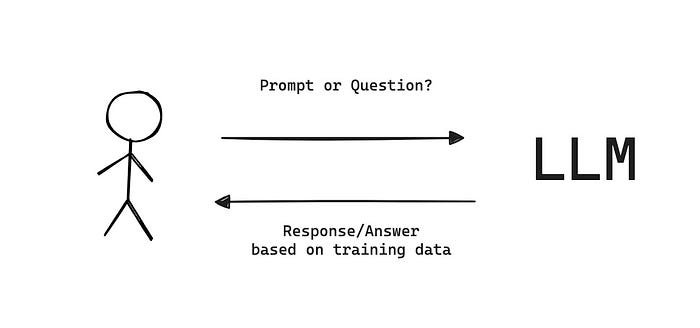
- But if the data is too general, out of date, or you need the data that specific to your business?
- So? Retrieval-Augmented is meaning we will placing the data source (somewhere else) and called it documents.
- Then before LLM create the response, We will retrieve the similar documents and attach together with prompt and send it to LLM for consideration of answer.
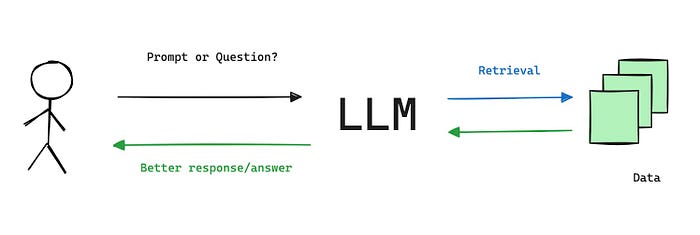
More information about RAG, Please kindly check here. I think this is the best one.
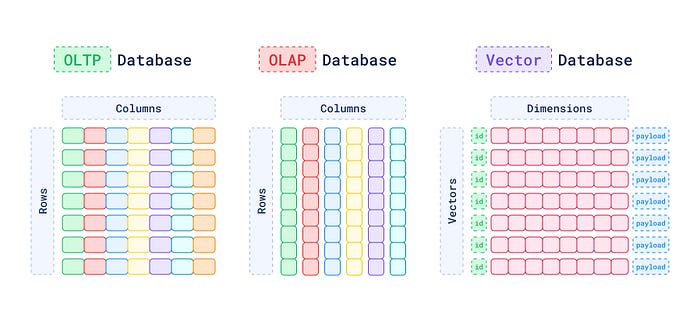
Vector Database
Vector Database is the database which designed to store data as vector (series of numerical).
- Inserting => Transform document/chunk of text to vector and store to database
- Retrieving => Searching data by similarity/context of data and return. (Similarity search)
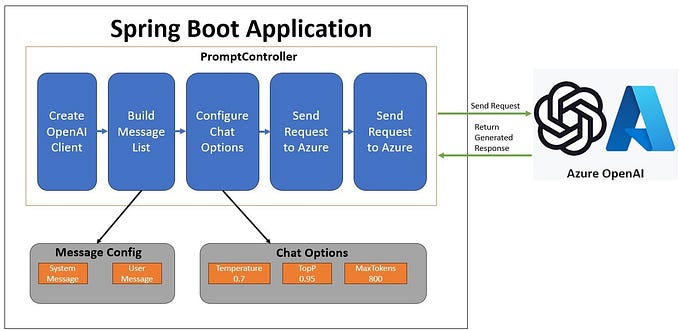
Spring AI Project
Spring AI has inspiration from LangChain (Python) which able to integrated with AI and many LLM. As of now, There are options for models and vector database. You can see the documentation of Spring AI directly on the site.
Vaadin
Vaadin is the framework to create web application with Java/Kotlin. Nothing much, I just want to trying something with Vaadin so I took the chance. If you interested, you can start the project by below site.
Note: Personally, It’s easier to create web application in JavaScript/TypeScript but if I compare with JSP (Java Server Pages). Okay, Vaadin is better. 😅
Get started
GitHub Repository + Concept
Our concept
- Create something that can response the existing data and help me write the code
Here the example result of this project
Discuss Tech Trend
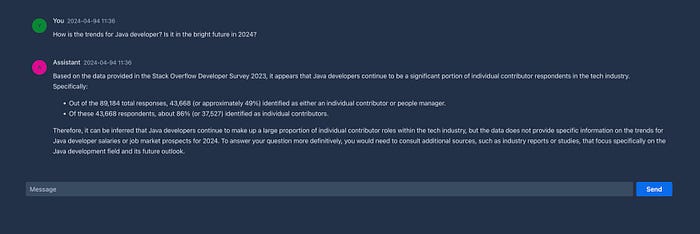
Pair Programming (Not much impressive for experienced developers)
Feasibility for integration
Let’s manual test with Ollama on locally
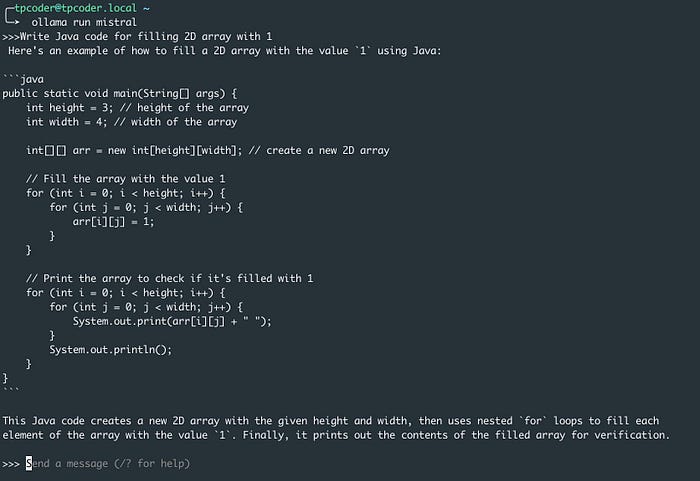
Okay, Then integration to our Vaadin project with Spring AI. Below are the relate configurations.
spring:
ai:
ollama:
base-url: ${AI_OLLAMA_BASE_URL:http://localhost:11434}
chat:
options:
model: mistralLet’s implement the idea!
It’s time for my pet project 😅. I split to this below steps
- Setup for RAG
- UI by Vaadin
- Create communication flow
Setup for RAG
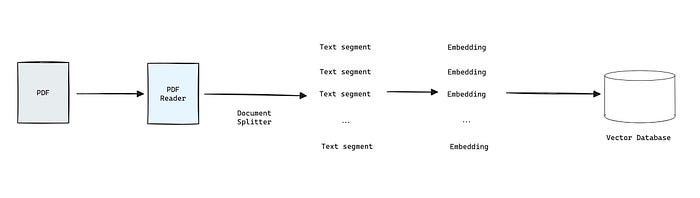
In this project, I used Apache Tika for read PDF file because I have some problems with spring-ai-pdf-document-reader
If you want to get the data like my project, I used the Stack Overflow Developer Survey 2023, Please kindly go to the site and save as PDF by yourself and place it under classpath resource /resources

And when the application start, The process will start read the PDF and storing data to embedded vector database.
Note — It’s very slow from my laptop. My application is ready after an hour.
UI by Vaadin
It’s the simple message input for receiving prompt (I tried to create UI like ChatGPT anyway but using Vaadin)

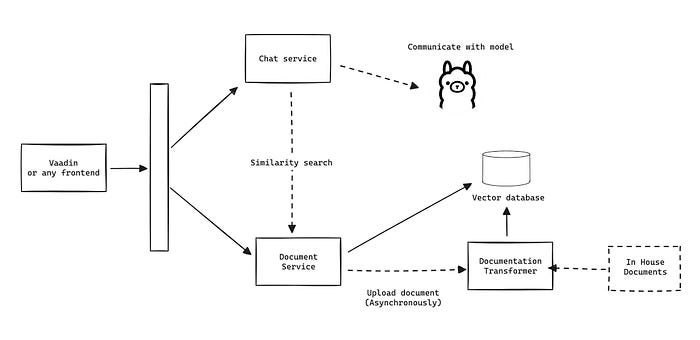
Create communication flow
Last but not least, We will create service to communicate with model by attached system prompt by using system-qa.st and we will replace it by using HashMap and then use SystemPromptTemplate to create message before sending to LLM
Enhancement suggestion
If you follow all steps here, You can see a lot of thing need to be improved in the future. Here are my suggestions
Separate RAG worker and Frontend component
Currently, This is my project looks like
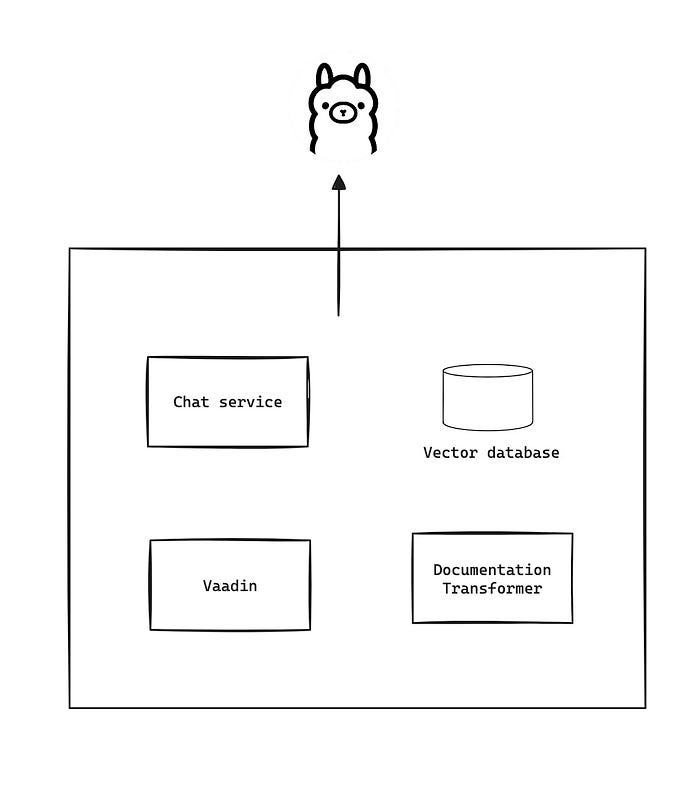
I believe it’s better if we separate workload into distributed system.
Use proper vector database instead of embedded simple one
Instead of embedding which consume massive memory. If we need to promote to upper environment or open to end-user. I think use proper vector database is much better.
As of now, Spring AI has these options
- Azure Vector Search — The Azure vector store.
- ChromaVectorStore — The Chroma vector store.
- MilvusVectorStore — The Milvus vector store.
- Neo4jVectorStore — The Neo4j vector store.
- PgVectorStore — The PostgreSQL/PGVector vector store.
- PineconeVectorStore — PineCone vector store.
- QdrantVectorStore — Qdrant vector store.
- RedisVectorStore — The Redis vector store.
- WeaviateVectorStore — The Weaviate vector store.
My issues
My laptop cannot catch up this setup — GG Me

I have attached my laptop spec which used for running Spring Boot + Ollama + Embedded Vector. It’s consuming a lot of CPU when start communicate to Ollama. I believe you might have better result than mine if you have laptop that has higher computation power. I don’t have budget to buy new one e.g. M1, M2, M3. 🥹
spring-ai-pdf-document-reader cannot work well with some pdf
I use spring-ai-pdf-document-reader and got OOM Killed because of some font setting of PDF Box
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-pdf-document-reader</artifactId>
</dependency>After spending around 4 hours, I change to Apache Tika by using spring-ai-tika-document-reader instead.
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-tika-document-reader</artifactId>
</dependency>My prompt is not efficient enough
System Message is the key factor to optimizing result from LLM. You can see my system message is not the best. Some sentence I use other generative AI to help think system message.
Alternative model if needed
Currently I used Mistral. Anyway, you can try alternative model by exploring more on Ollama library
Conclusion
That’s it for my pet project. It’s really small but I have made my hand dirty by exploring and making something
- Spring AI
- Integrate between Spring AI + Ollama
- RAG
- Try Vaadin
Anyway, Thank you for reading through this blog post. Apologize if it’s not meet your expectation. See you in the next blog post. 🙇♂️
Facebook: Thanaphoom Babparn
FB Page: TP Coder
LinkedIn: Thanaphoom Babparn
Website: TP Coder — Portfolio